 (10)")
")
As a Marketing Manager for entertainment platforms, you want to connect with your users when they are off your platform. The question is: how to connect in the best way, making sure to send each of your users the right content at the right time? How to adapt your communication to maintain them engaged and avoid churn risk?
Personalization is key, yet Personalization at Scale is a challenge. From a technical point of view, in addition to personalizing the communication, the challenge is to identify user segments directly linked to actionable personas.
In order to be usable for marketing campaigns, the user segmentation must be
- Explainable: each segment should have distinct characteristics that are explainable by business logic.
- Efficient and scalable: the segmentation engine should dynamically segment users into the personas and detect the transition of users from one persona to another. The approach should scale to process billions of user interactions daily.
- Actionable: The segments should enhance the downstream personalization objective, personalization strategy can be directly built based on the segments.
Implementation: The 3-Layered Approach to User segmentation
Spideo collects user interaction data from streaming platforms, allowing us to analyze usage and consumption patterns. While standard machine learning methods like Kmeans or hierarchical clustering offer quick solutions for grouping users, they lack the necessary controllability, interpretability, and scalability for our business needs. These methods are also sensitive to small data changes and are computationally inefficient.
Instead, we adopted a 3-layered approach to create actionable user segments tailored to business objectives.
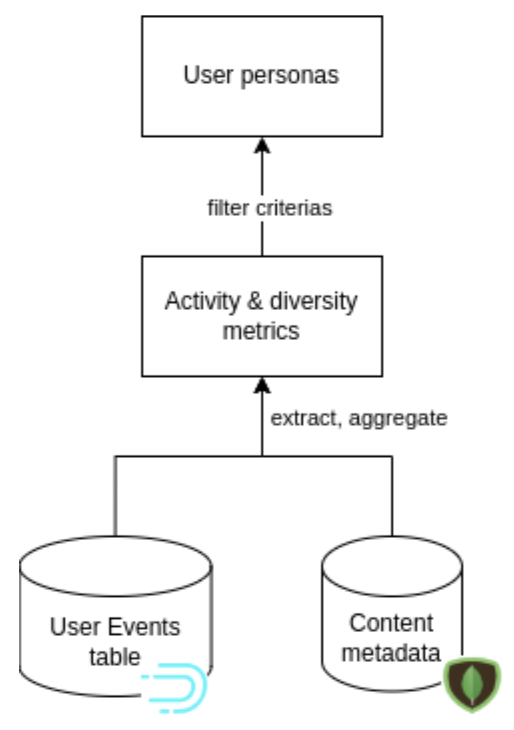
Layer 1: Raw data layer: The first layer of computation consists of raw user interaction events and content side information (semantic metadata, availability rights, release date etc.). The user interactions consist of events from users’ navigation in the platform (e.g: click, watch, playlist, bookmark etc.). The event store is modeled to consume near real-time streams of user interactions and read-optimized for downstream retrieval by the aggregation layer.
Layer 2: Activity and consumption metrics: In the second layer, for each user, we automatically derive business-oriented metrics to describe the usage patterns on the platforms, such as:
- Activity Period: Consecutive days of activity in the platform
- Type of activity period: For each activity period, a type is assigned based on the dominant interaction type during the activity period (e.g: user is mainly watching content / browsing / bookmarking etc.) and based on types of content being consumed during this period (e.g: series / movie etc.)
- Content diversity: For each activity period, the diversity of the content being consumed is measured based on the semantic metadata information of the contents
- Ghost and sleepy regions: Periods of inactivity with sparse and sporadic spikes in activity without any clear interest patterns are categorized as Ghost regions. Long periods of complete absence of activity are considered as Sleepy regions. Metrics such as duration, user’s genre affinity etc. are further considered for more finer grained pattern discovery within these regions of inactivity.
Layer 3: User Personas
Based on the consumption metrics and business criteria, we perform an information filtering to segment users into respective personas. We will take a couple of examples of how the personas are defined
Binger: A user within a specific timeframe who is showing clear interest in a specific series, watching multiple episodes of that series during an activity period is considered a Binger.
Ghoster: A user within a timeframe showing clear prolonged patterns of periodic inactivity and with very sparse and sporadic activity in the platform (mostly clicks and exploration without any clear consumption) and no specific interest to particular types or genres of contents are classified as Ghosters.
Each generated segment is associated with a level of churn risk, and downstream personalization strategies can be adapted to address each of the segments in a relevant manner.)
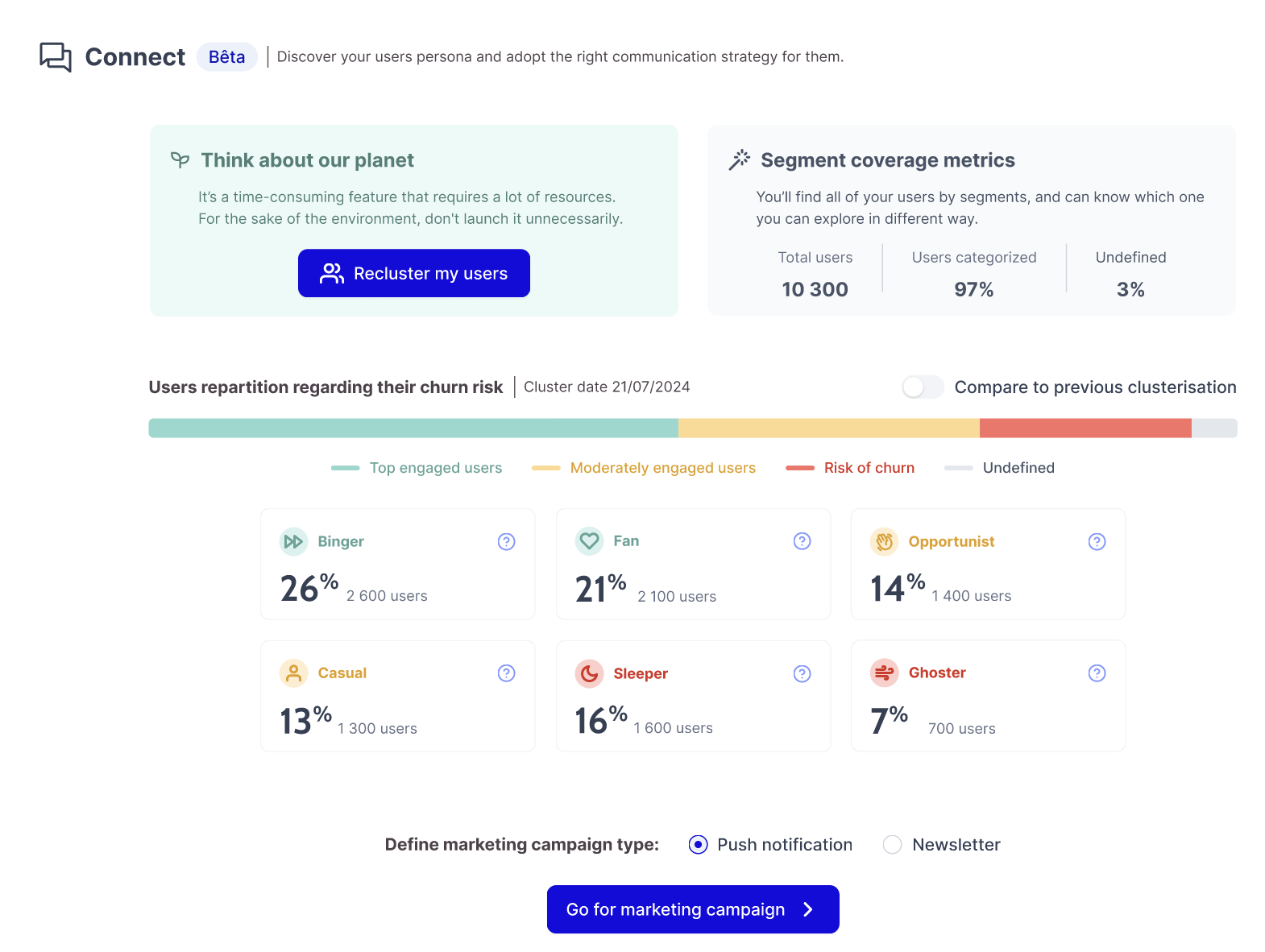
The Tech Stack behind Spideo Connect
The three layered approach can be summarized by the following simplified data flow diagram. User interactions on the platform (click, play, bookmark, etc.) are stored in the read optimized user events table hosted on Apache Druid. Content metadata is stored in MongoDB databases.The events are aggregated and transformed to build the metrics layer by DuckDB and python jobs. Filtered user personas are ingested in the dedicated table on Apache Druid.
What’s next for Spideo Connect?
The user segmentation engine is already deployed in production, and we are currently working on improving the analysis in the following directions:
- Granular temporal patterns: Our ongoing work involves processing finer grained temporal patterns of User’s activity data (e.g: Time of the day, Day of week / month etc.). This work is critical to further enhance the impact of the downstream personalization campaigns and communicate the right content to the right user at the right moment.
- Multiple persona problem: Users can be segmented into multiple personas within a specific time period. This is not very useful and can be difficult to manage in the downstream content marketing use cases. Defining mutual exclusivity among the user personas is not trivial, as they are built with different underlying metrics, and several approaches need to be benchmarked.
- Modeling Behavior drift: When a user changes behavior and transitions from one persona to another, the shift can indicate substantial change in their risk profile. For example, when a Binge watcher becomes a Ghoster, the risk of churn increases. The current implementation takes into account the various profiles of a given user over time. Future work involves modeling the sequential and temporal transitions of users from one persona to another, in order to unlock predictive insights on consumption and churn risk.
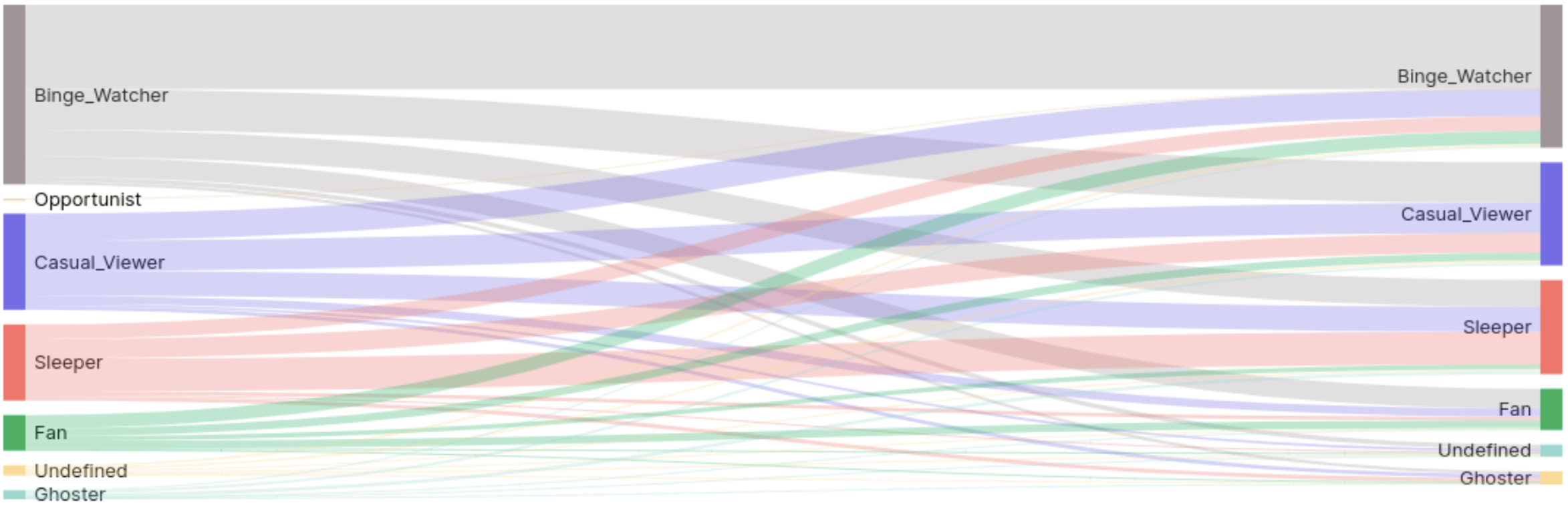
Takeaway: User Segments for effective personalization
Spideo Connect allows the automatic generation of user segmentation based on the combination of consumption patterns and content knowledge. Our 3 layered approach ensures explainable segments that are both scalable and directly usable in personalizing offline communications to each user’s persona
Head over to our Linkedin post to watch our VP Product, Némésis, discuss how connect can enhance your user segmentation strategy, and stay tuned for more blog posts on personalization, recommendation and beyond!